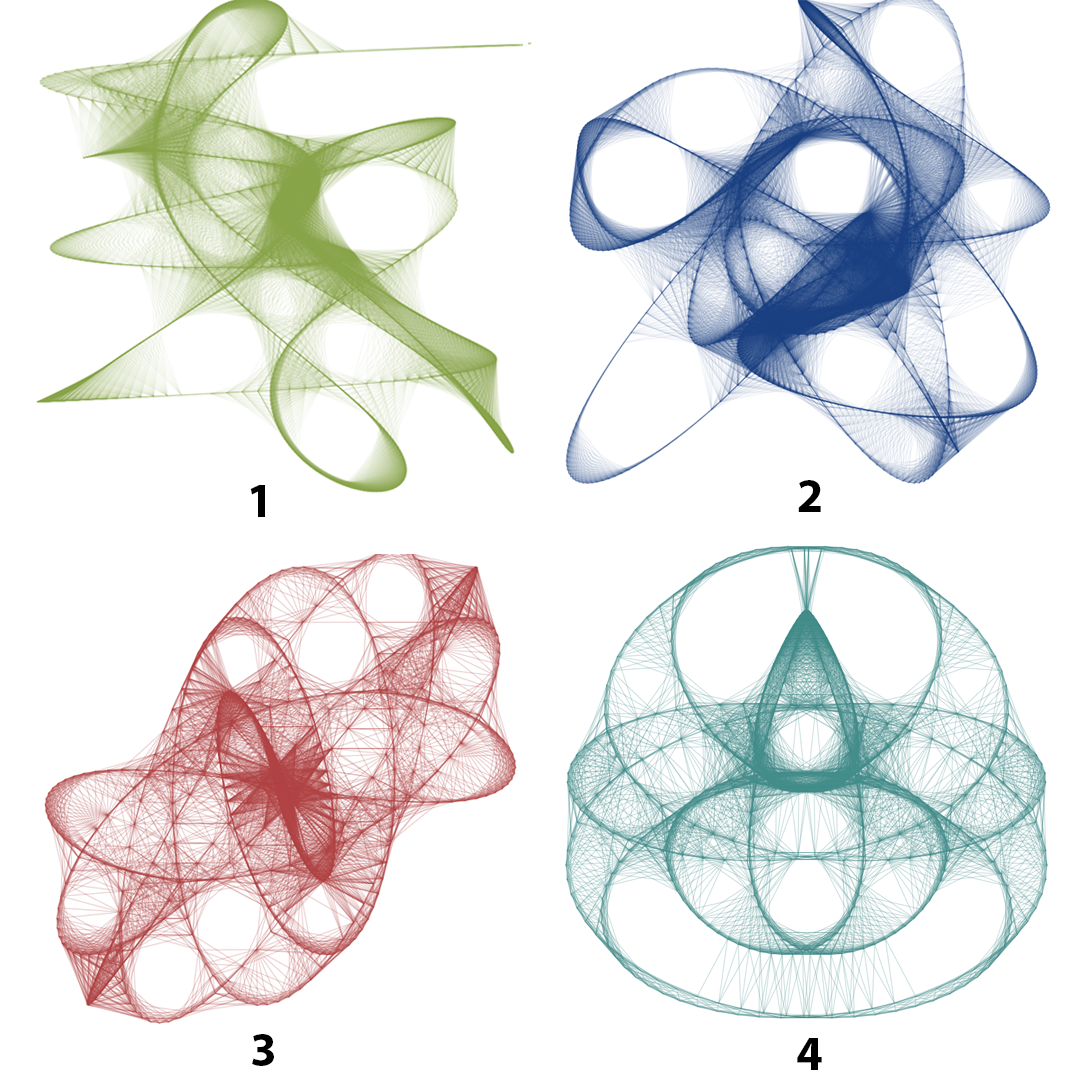
“Through the interplay of complex information with graphic design and programming, new and fascinating visual worlds are emerging where the coincidental is shaped to help correlations become visible.” – Karin and Bertram Schmidt-Friderichs, “Generative Design: Visualize, Program, and Create with JavaScript.js”
When it comes to designing a new product, whether it is a piece of software or hardware, manual sketching and planning used to be inevitable. However, different techniques have been developed over the years, to aid the lengthy process of iterative design. One such technique is the evolutionary computational approach and more specifically genetic algorithms. Genetic algorithms have proven to be sufficient tools for many approximation tasks at much lower requirements for computational power than more complex machine learning methods. Drawing inspiration from various art projects based on evolutionary algorithms, the idea of this project was to create an interactive generative art tool. Traditional Lissajous curves are modified by applying various traits such as noise and color, controlled by a genetic algorithm. The purpose of the tool was to examine how the inclusion of color in the generated art, affects the user’s preference for symmetry over entropy. The project was written in Java Script, HTML and CSS. Additionally, an innovative method for converting qualitative data into quantitative, known as Sentiment Analysis, was utilized. VADER (Valence Aware Dictionary and sEntiment Reasoner) is a Python library utilizing a sentiment lexicon, that represents a list of words which are labelled as either being positive or negative. VADER has been very successful at analyzing reviews, social media posts or newspaper editorials. The advantage of using this library is that it does not require any pre-training of the data, it is very computationally lightweight and together with outputting whether a sentiment is positive or negative, it also quantifies those two traits.
The tool is available at: https://tinyurl.com/r4uxzep (color version) and http://tinyurl.com/wxrl93q (grayscale version).

The idea behind genetic algorithms
In the 1950s, numerous well-known scientific names from the area of computation technologies worked on the idea of what would later come to be known as genetic algorithms. This shift in the direction of development of computational systems was inspired by the notion of using the natural process of evolution as an optimization tool for engineering problems. More specifically, the idea was to approach the solving of a certain problem by obtaining a population set of potential solutions, using techniques and operations, such as natural selection and natural genetic variation. These are processes that occur in a natural manner, as a result of the interaction between the different systems of living organisms, their traits and the conditions of the environment by which they are surrounded. In the case of natural selection, this is one of the most important building blocks of evolution, as it is the main mechanism responsible for the change of heritable characteristics of a population, over the span of generations. More specifically, this is the process of reproduction and survival of individuals due to the definitive distinctions in their phenotype, which in genetics simply stands for the composite of observable characteristics of a given organism. Respectively, genetic variation stands for the differences in the DNA, occurring as a result of the above described processes. This variation can be either between the individuals within a certain population or between different populations altogether.
Genetic algorithms rely on three main concepts – variation, selection and heredity. To be more specific, these concepts are represented in 5 main phases in the life of the algorithm:
- Initializing initial population of elements (potential solutions)
- Assignment of fitness for each element based on a predefined fitness function
- Selection of the fittest (most optimal) solution of the current population
- Crossover
- Mutation
Starting with the initialization phase, a population of initial random solutions elements is generated. The reason for the arbitrary nature of this initial set of solutions is to provide a sufficient level of initial variation within the constrains of the problem, thus providing a higher chance of quicker path to the optimal solution. Each member of the population is characterized by a genotype, consisting of genes, usually represented in the form of a string of numbers, varying within certain constrains.
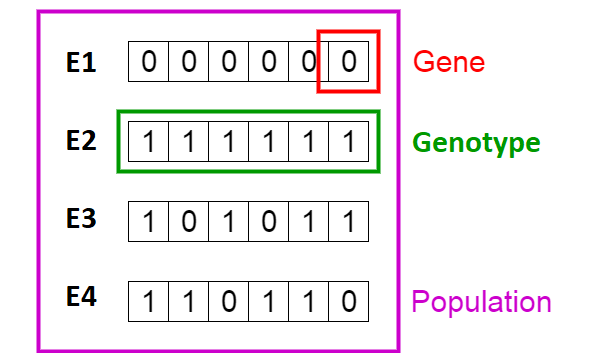
Next, a fitness score is assigned to each element based on a fitness function modeled after the nature of the problem that is to be solved. More specifically, the fitness function represents the criteria by which the individual solution proposals are characterized. After the fitness assignment, the two fittest (with a highest fitness score) elements of the population are chosen for sources of genetic material for the next generation. It is important to mention that the number of parental elements does not necessarily has to be limited to only two, as the selection phase can be optionally executed in such manner that the genotype of the next generation is formed from the genes of all members of the parent generation, as long as their fitness score is higher than zero. This way, the parents with the highest score will contribute the most from their genotype, while the ones with lower, will add only slight change to the newly generated set. Additionally, the selection phase includes two sub-phases that are crossover and mutation. The crossover process, being the core of every GA, represents the exchange of genes between the two fittest parents, limited by a randomly set crossover point.
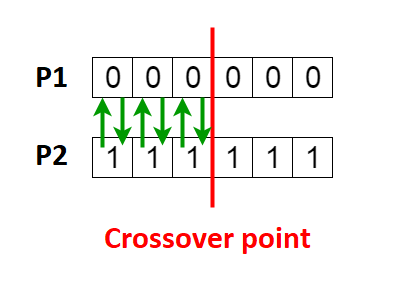
Before the completion of the crossover phase and re-population of the set of solution elements with the newly generated offsprings, the mutation phase takes place, where depending on a predefined mutation probability, each child element receives a number of randomly generated genes. This is done in order to ensure consistency of the variation in every new generation, preventing the algorithm from reaching a state of convergence without reaching the optimal solution of the problem.
Lissajous curves
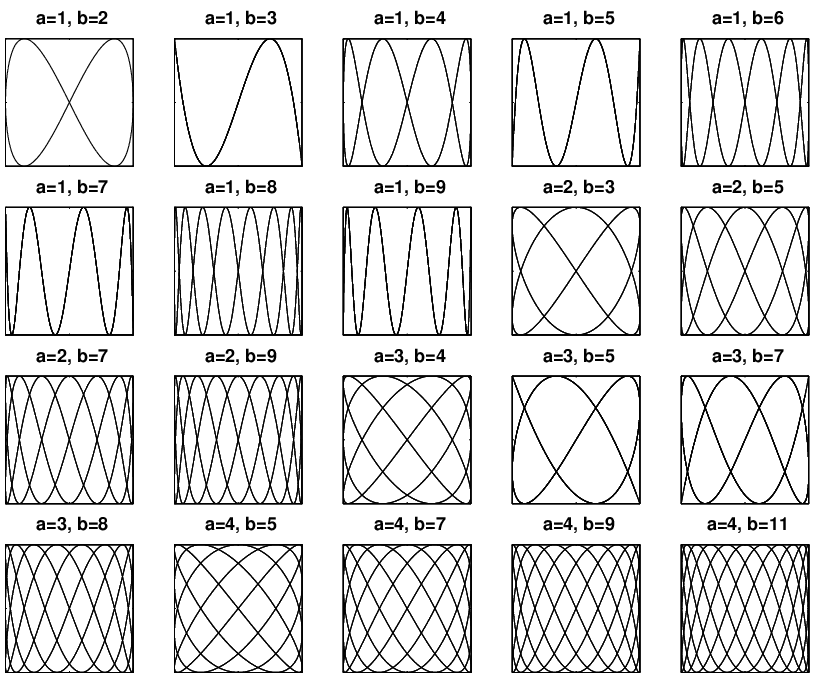
Lissajous curve or figure is a name for graphs that represent trajectories of points with sinusoidal movement. They are named after Jules Antoine Lissajou who studied them in great detail in 1857 when he used a container filled with sand tied to an end of a compound pendulum. A thin stream of sand pouring from the container at the end of the swinging pendulum resulted in these curves. The basis of Lissajous curves are the following parametric equations:
![\[x = A*sin(at + \delta)\]](https://georgisworks.com/wp-content/ql-cache/quicklatex.com-d106c44b6af4d581af8df489940972e0_l3.png "Rendered by QuickLaTeX.com")
![\[y = B*sin(bt + \gamma)\]](https://georgisworks.com/wp-content/ql-cache/quicklatex.com-f3f6ef4ee6ebd2c55a6313a9ae5ed6f0_l3.png "Rendered by QuickLaTeX.com")
The main parameter describing a shape of the figure is the ratio between a and b. By changing these values, different shapes ranging from simple ellipses and circles to complex figures and knots can be produced. The ratio also decides how many lobes are going to be present on the figure.
Generative interactive design
A big part of computational aesthetic evaluation revolves around evolutionary systems. These systems have the task of exploring spaces in search for optimal solutions to various problems. The evaluation of each possible solution is carried based on the fitness value which is a single score combining various qualities that are requirements for the output of the evolutionary system. The issues with computer assigning these fitness values are most prominent when it comes to generating and evaluating art. This is where interactive evolutionary computation comes into place.
There are several formulaic approaches that can be used for computational aesthetic evaluation. Some examples are Fibonacci series, Golden Ratio, Zipf’s law or Birkhoff’s aesthetic measure. The Birkhoff’s aeesthetic measure is often considered to be the earliest foundation of computational aesthetics. George David Birkhoff formulated aesthetic measure as:
![\[M = order/complexity\]](https://georgisworks.com/wp-content/ql-cache/quicklatex.com-71c52fa9286d6ab85be9ce8e5bfa48fc_l3.png "Rendered by QuickLaTeX.com")
The way how Birkhoff though about complexity was as an amount of effort a human has to use when focusing on a certain object in order to experience aesthetic reward. A way how Birkhoff determined a complexity of an object was for example by counting polygon edges and vertices. However, when evaluating aesthetic, the focus is not only on the complexity. An order needs to be present in harmony with complexity for something to be perceived as appealing. For Birkhoff, the order was found in symmetry, repetition, rhythm but also in ambiguity.
However, all of these power laws have proven to be sufficient only as a supplementary techniques when it comes to evaluating generative art. Previous attempts at creating software that automates the fitness scores had limited success mainly because of poor generalization. Assigning fitness scores manually has its advantages and disadvantages. Using humans to assign the fitness scores when evaluating evolutionary art has been considered a dominant practice.